
(1)先上完整代码(可下载单曲):
<code> #第1部分#第2部分import re
import requests
import bs4
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"}
tip = "本程序只限下载QQ音乐(https://y.qq.com/)\n此程序适用于非客户端即可下载音乐\n请输入你需要下载歌曲的编号(song/与.html中间的编号):\n"
number = input(tip)
baseurl = "https://y.qq.com/n/yqq/song/" + number + ".html"
musicurl = "https://link.hhtjim.com/qq/" + number + ".mp3"
vkey = "<Response [404]>"
findTitle = re.compile(r'<h1 class="data__name_txt" title="(.*?)"')
def getURL(baseurl):
req = requests.get(baseurl,headers=headers)
html = req.content.decode('utf-8')
soup = bs4.BeautifulSoup(html,'html.parser')
for item in soup.find_all("div",class_="data__name"):
item = str(item)
title = re.findall(findTitle,item)
for title0 in title:
title1 = title0 + ""
title2 = re.sub(" ","_",title1)
chrome_options = Options() #音乐</code>#第三部分chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
browser.get(musicurl)
sleep(3)
get_musicurl = str(browser.current_url)
browser.close()
browser.quit()
print("已搜索到此歌曲")
html0 = requests.get(get_musicurl,headers=headers)
html1 = str(html0)
if html1 != vkey:print("正在下载...")
with open(title2+".mp3", "wb") as code:
code.write(html0.content)
print("下载完成")
else:
print("此歌曲的vkey值未找到\n无法下载")
getURL(baseurl)
(2)逐步分析:
1.导入库
re库, bs4库, requests库就不多说了。分别用来请求和筛选数据的
selenium库用来做模拟浏览器网页跳转。比如:python模拟在浏览器输入a网址,并且会跳转到b网址。有的人会问,为什么要这么做?我回答:因为a网址易找规律,而b网址很难发现规律,但b网址又是通过在浏览器中输入a网址并且回车之后跳转出来的。因此需要用到selenium库
ps:使用selenium库中的webdriver方法时,需要添加环境变量。下面教程转载自:https://www.cnblogs.com/lfri/p/10542797.html
安装selenium
selenium可以直接可以用pip安装。
安装chromedriver
下载chromedriver的版本一定要与Chrome的版本一致,不然就不起作用。
有两个下载地址:
http://chromedriver.storage.googleapis.com/index.html
https://npm.taobao.org/mirrors/chromedriver/
当然,你首先需要查看你的Chrome版本,在浏览器中输入chrome://version/
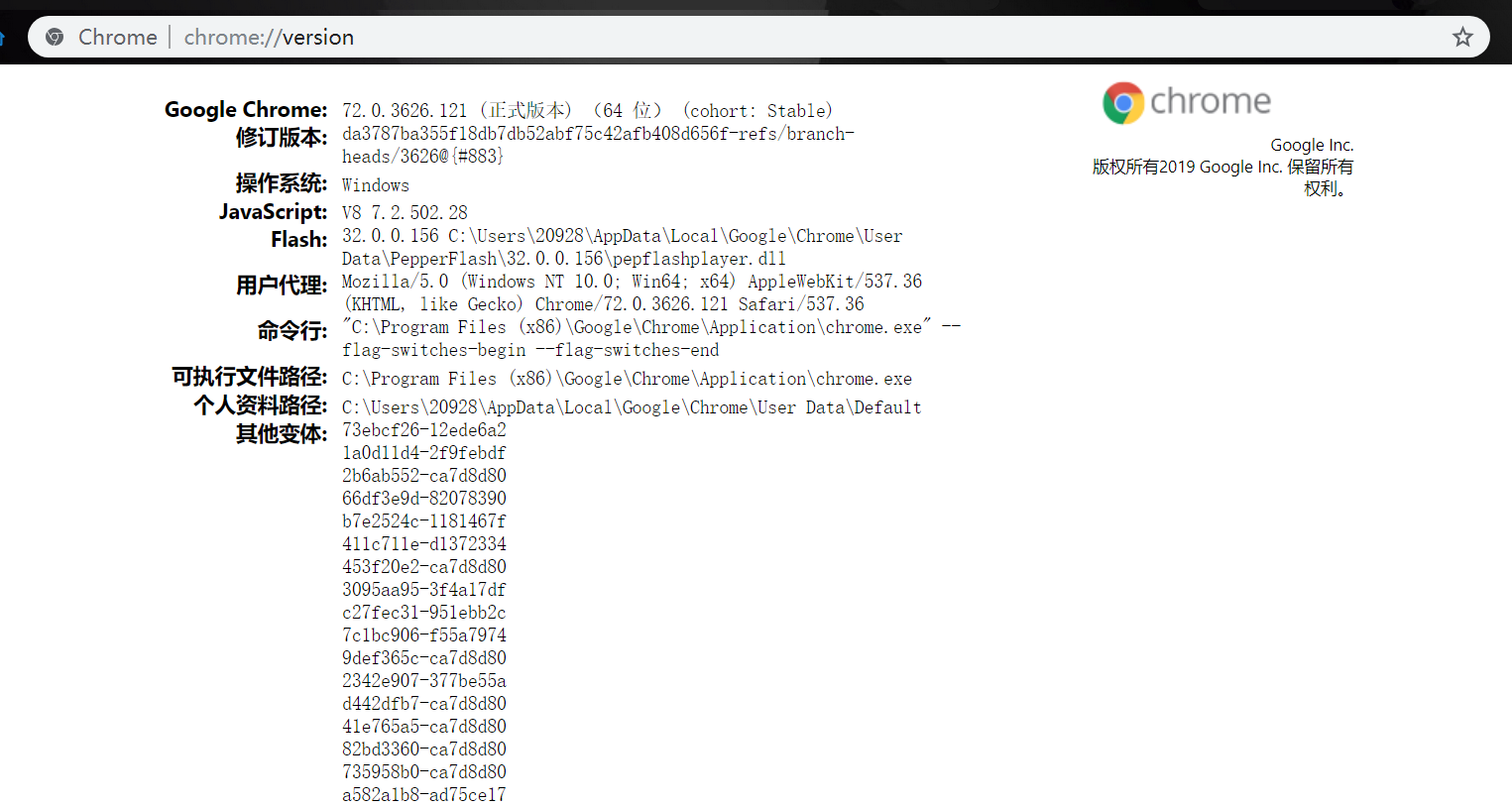
例如我的版本是72.0.3626,所以下载

配置
解压压缩包,找到chromedriver.exe复制到chrome的安装目录(其实也可以随便放一个文件夹)。复制chromedriver.exe文件的路径并加入到电脑的环境变量中去。具体的:
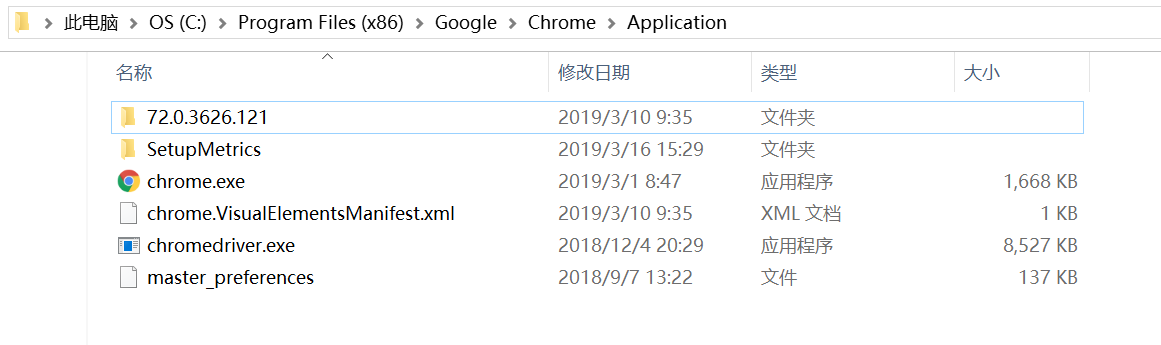
首先当然是下载Chromedriver:(下载路径:https://sites.google.com/a/chromium.org/chromedriver/downloads)
(这个网站可能需要翻墙)还有一个网站可以百度一下
然后就是将你下载完成的chromedriver.exe文件解压到C:\Program Files (x86)\Google\Chrome\Application这种路径下
不过我的是这种C:\Users\AppData\Local\Google\Chrome\Application就是谷歌的安装目录,(右击谷歌选择打开文件位置就行了)
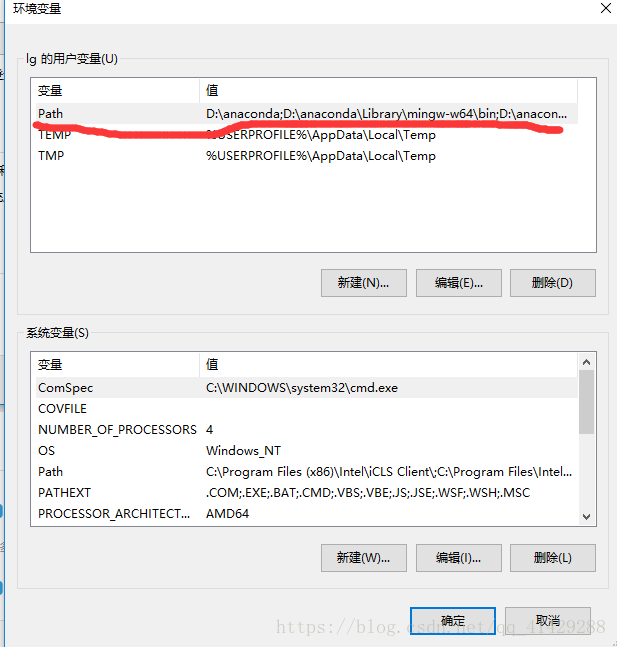
最后到了最关键的一步:就是配置环境变量了
首先点开此电脑(win10)->;属性
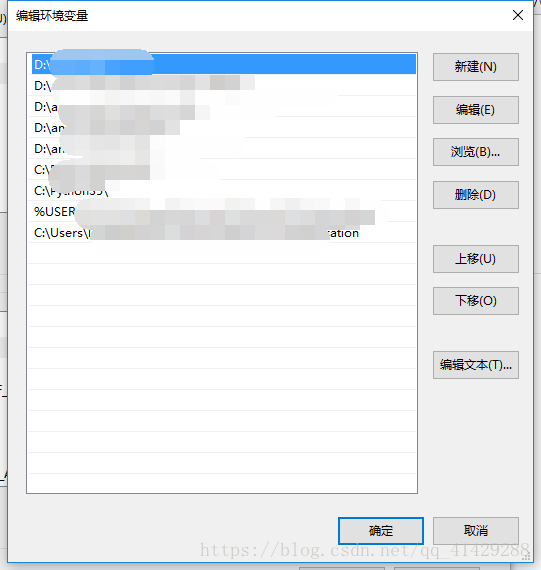
进入环境变量编辑界面,添加到用户变量即可,双击PATH,将你的文件位置(C:\Program Files (x86)\Google\Chrome\Application\)添加到后面。
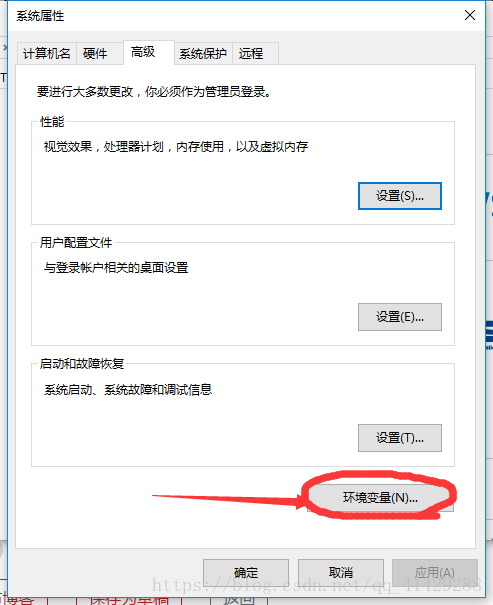
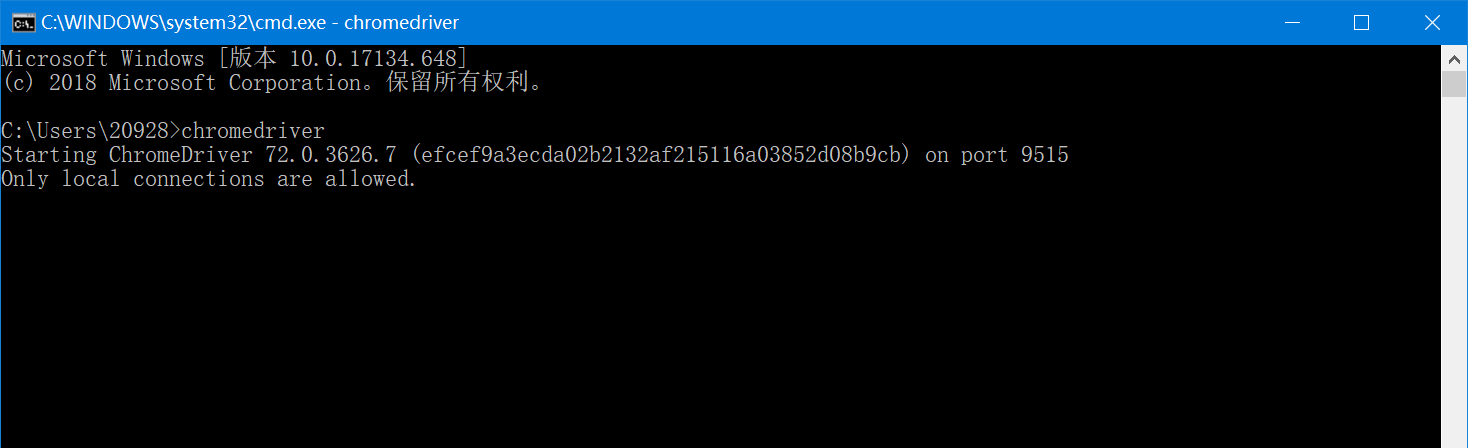
完成后在cmd下输入chromedriver验证是否安装成功:
2.使用selenium库
转载教程:https://blog.csdn.net/qq_24499417/article/details/83990954
本例采用selenium获得最终的网页链接。原来的网址是:http://www.baidu.com/link?url=ojjD2hHxviDl0j4T6MCQzRaQYUyYe0BX2aCXcNI5UliRtQum2Y7XH9_xZ08mzOJH,网页完全加载完成后的网址变为了https://weibo.com/niceinapp?is_hot=1。代码如下:
"""
Created on Mon Nov 12 13:33:40 2018
@author: FanXiaoLei
"""
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
req_url = "http://www.baidu.com/link?url=ojjD2hHxviDl0j4T6MCQzRaQYUyYe0BX2aCXcNI5UliRtQum2Y7XH9_xZ08mzOJH"
chrome_options=Options()
#设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
# 开始请求
browser.get(req_url)
sleep(5)
#打印页面网址
print(browser.current_url)
#关闭浏览器
browser.close()
#关闭chromedriver进程
browser.quit()
3.对vkey值(响应码)进行分类
如果vkey等于403,也就是此网页不能访问,也就是搜索不到歌曲,因此无法下载
如果vkey不等于403(此处只等于200,不会等于418或者其他),顺利访问网页,可以搜索歌曲,最后下载。
叨叨几句... NOTHING